Stephen McKeown, Scott Fischaber, Roger Woods, John McAllister and Eoin
Malins
Queen’s University Belfast
Abstract
With the increased inclusion of Field Programmable Gate Array (FPGA) systems in heterogeneous embedded computing platforms for high end Digital Signal Processing (DSP) systems such as radar and sonar, significant system design issues are being presented to the FPGA design methodology community. In particular, bridging the design time gap between established multiprocessor rapid implementation approaches and the more hand-crafted approaches traditional for FPGA-centric platforms is problematic. This situation is exacerbated by the desire to address pressing low-level implementation concerns of FPGA devices for specific applications, in particular achieving the desired real time performance inside stringent memory and power budget constraints. The low level nature of these issues is such that achieving appropriate performance using a system level design procedure is currently difficult.
This paper addresses low power system level design of high end signal processing systems. Previous work at Queen’s University has lead to the establishment of the Abhainn [1] approach to rapid system level design of DSP systems on FPGA-centric embedded platforms. In Abhainn, a geometric dataflow graph (DFG) modelling language is used to represent the system functionality, allowing the designer flexible algorithm level control of the structure of the parts of the system mapped to dedicated hardware. This enables exploitation of variable parallelism levels in the algorithm to good effect to meet the real time processing requirements of the system. This description is exploited by Muir [2], a rapid hardware implementation toolset in Abhainn which integrates third party intellectual property (IP) cores to realise the DFG actors. These are wrapped in automatically generated core wrappers, allowing variable levels of actor sharing as the numbers of actors in the DFG is altered.
In this paper, work is presented in applying this design approach to the design of a real application namely a Fixed Beamformer (FBF) spatial filtering system design example. For this paper, an example 16-channel complex acoustic beamforming system is employed. The structure of the system under analysis is outlined in Fig. 1.
|
|
Fig. 1: Generic FBF System Structure |
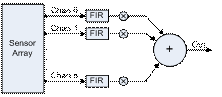
In Muir, the complex Digital Receiver (DRx) FIR filters and the complex scaling multipliers are realised using library IP components. Whilst the algorithm has a fixed 16 channel functionality, the Muir core network realisation approach enables flexibility in the structure of the implementation by allowing sharing FIR and multiplier cores such that it can process variable numbers of channels of data in an interleaved or block processing fashion. In addition, whilst Muir is portable across target FPGA devices, it enables exploitation of device specific structures to efficient implementation.
These two aspects enable comprehensive implementation analysis from numerous viewpoints.
-
Algorithmic Level: Muir is driven from the algorithm level, i.e. the ‘shape’ of the algorithm is manipulated to influence core network structure.
-
Core Network Level: Variable levels of core sharing for processing of variable numbers of data channels in an interleaved and block processed manner.
-
Core Level: Variable levels of core pipelining employed.
-
Device Technology Specific: The FBF design example is targeted towards Xilinx VirtexII Pro FPGA technology, involving use of device specific manifestations of LUTs as 16-bit shift register (SRL16) or 16 element distributed RAM (DisRAM) components to provide the interleaved/block processing hardware sharing capability.
This paper presents both simulated and measured power results, for variable levels of core sharing, different types of memory manifestation, i.e. SRL and DisRAMs and varying levels of pipelining. The work shows how the system level optimisations are performed from a high level and the results indicate guideline techniques for low power system level design of high end DSP systems.
References
-
J. McAllister, R. Woods, D. Reilly, S. Fischaber and R. Hasson, “Rapid Implementation and Optimisation of DSP Systems on SoPC Based Heterogeneous Platforms”, Proc. Ffith International Workshops on Computer Systems: Architectures, Modeling and Simulation, pp. 254 – 263, SAMOS, Greece, July 19 – 21 2005.
-
J. McAllister, R. Woods, R. Walke and D. Reilly, “Multidimensional DSP Core Synthesis for FPGA”, Invited submission to Journal of VLSI Signal Processing Systems for Signal, Video and Image Technology, Special Issue on SAMOS IV. To be published May 2006.